PostgreSQL SQL优化 Filter 优化
1 背景知识
生产系统有一条报表统计SQL执行非常慢,分析后发现SQL写法上存在严重问题。在改写过程中,发现 PostgreSQL filter 子句不但可以完美地替换 case .. when 语句,而且使得SQL 语句的可读性非常好。
2 修改前的SQL及执行计划
CREATE TABLE t01(t01id1 integer ,typ01 integer);
CREATE TABLE t02(t02id1 integer ,typ02 integer);
insert into t01 values(generate_series(1,999999),generate_series(1,999999));
insert into t02 values(generate_series(1,999999),generate_series(1,999999));
EXPLAIN ANALYZE SELECT t01id1,
(SELECT count(*) AS cntyp1 FROM t02 WHERE t02id1=t01id1 AND typ01='1' AND typ02='1' ) AS typ11,
(SELECT count(*) AS cntyp1 FROM t02 WHERE t02id1=t01id1 AND typ01='1' AND typ02='0' ) AS typ10,
(SELECT count(*) AS cntyp1 FROM t02 WHERE t02id1=t01id1 AND typ01='0' AND typ02='1' ) AS typ01,
(SELECT count(*) AS cntyp2 FROM t02 WHERE t02id1=t01id1 AND typ01='0' AND typ02='0' ) AS typ00
FROM t01;
从语句写法就能看出,该SQL对于t2表重复多次访问,且由于采用了select + 子查询的模式,使得子查询只能使用SubPlan 方式,执行效率非常低。来看执行计划:
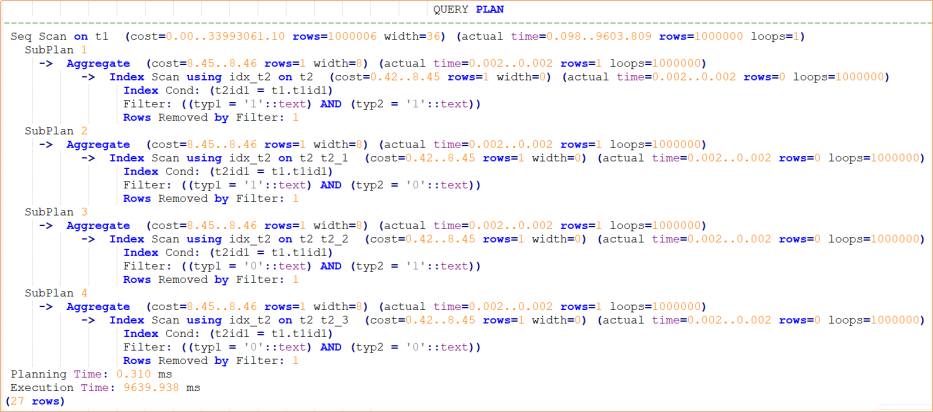
从执行计划得出,每个 subplan 大约消耗了 19425 开线,4个 subplan 共消耗了8s 。很明显,优化的方向是减少 t02 表的重复访问,同时去除 subplan。
Note
除了 case .. when,本例也可以用 group by,但可读性及灵活性均不如filter。不同的 Filter 可以设置不同的条件,统计的方法不限于 count 这一种聚合函数。
3 优化后的SQL及执行计划
针对以上场景,很容易就想到case .. when 语句,但考虑到相对逻辑复杂,且可读性差,这里使用filter 写法。具体修改如下:
SELECT t1id1,cntyp11,cntyp10,cntyp01,cntyp00 FROM t1 LEFT JOIN (
SELECT t2id1,
count(*) filter (WHERE typ1='1' AND typ2='1') AS cntyp11,
count(*) filter (WHERE typ1='1' AND typ2='0') AS cntyp10,
count(*) filter (WHERE typ1='0' AND typ2='1') AS cntyp01,
count(*) filter (WHERE typ1='0' AND typ2='0') AS cntyp00
FROM t2 GROUP BY t2id1 ) t2 ON t1id1=t2id1;
执行计划如下:修改后执行时间从 9s 降到了2s

4 总结
调优SQL代码时,需要注意减少表访问次数,尽可能将多个对同一张表的访问操作合并到一条SQL中。